Is there anyone working predominantly in NLP who doesn’t know what BERT is?? I highly doubt that.
Don’t confuse yourself into thinking that I am going to talk about the Sesame Street TV series. The image for Bert was taken from this TV series where there are two muppets named Bert and Ernie. :)

What is BERT?
Bidirectional Encoder Representations from Transformers commonly called as BERT, is a pre-trained NLP model developed by Google. BERT has achieved SOTA performance on multiple NLP tasks. Unlike W2V, Glove word embeddings, BERT generates contextual word representations. Transformers are the basic building blocks of BERT, BERT is built over the enocders section of Transformers. BERT small and LARGE has 12, 24 encoders respectively.
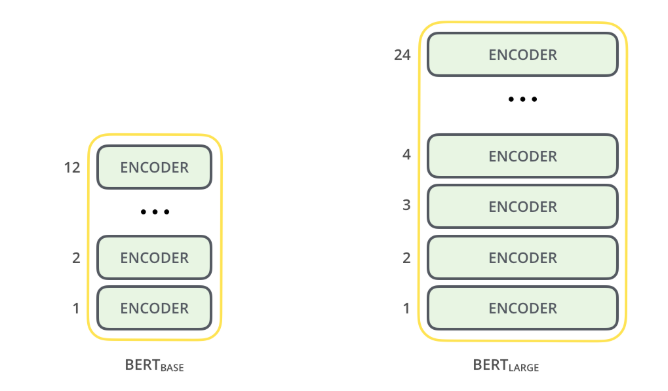
Pre-training BERT from scratch would be an onerous as we would need huge corpus of data and lots of GPUs. Huggingface community has provided more than 1,500 pre-trained models. We will be using bert_base_uncased model which was trained on lower-cased English text containing 12-layer, 768-hidden, 12-heads, 110M parameters.
On the other hand, there is a BERT model trained on 152 million sentences from the StackOverflow’s 10 year archive - BERTOverflow. We will be comparing BERTOverflow and generic BERT model vocabulary.
Firstly, install transformers library.
!pip install transformers
Loading bert_base_uncased and BertOVERFLOW
from transformers import BertTokenizer, BertModel, AutoTokenizer, AutoModelWithLMHead
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert_model = BertModel.from_pretrained('bert-base-uncased')
stack_tokenizer = AutoTokenizer.from_pretrained("jeniya/BERTOverflow_stackoverflow_github")
stack_model = AutoModelWithLMHead.from_pretrained("jeniya/BERTOverflow_stackoverflow_github")
Applying Tokenizers to a sentence
sentence= "The reference assemblies for framework “.NETFramework,Version=v4.6.2” were not found"
bert_tokens = bert_tokenizer.tokenize(sentence)
stack_bert_tokens = stack_tokenizer.tokenize(sentence)
while len(stack_bert_tokens)<len(bert_tokens):
stack_bert_tokens.append("")
print('{:<12} {:<12}'.format("BERT", "OverflowBERT"))
for tup in zip(bert_tokens, stack_bert_tokens):
print('{:<12} {:<12}'.format(tup[0], tup[1]))

Applying Tokenizers on specific words
words = ['Scikit-Optimization',
'Docker-Image',
'root@localhost',
'XMLHttpRequest'
]
for word in words:
print('\n','Word:',word, '\n')
bert = []
stackbert = []
bert.extend(bert_tokenizer.tokenize(word))
stackbert.extend(stack_tokenizer.tokenize(word))
print('BERT')
print(bert)
print('BERTOverflow')
print(stackbert)
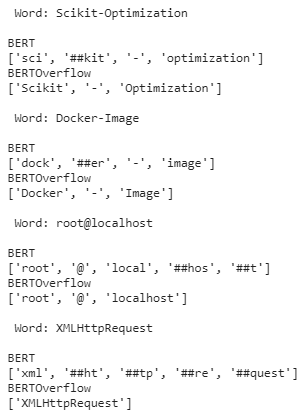
BERTOverflow has embedding for NETFramework,scikit, Docker, localhost, and XMLHttpRequest whereas BERT broke down these words into subwords.
Number of single character tokens as well as the single character tokens preceded by ‘##’ in vocabulary
char_bert,char_stackbert= [],[] # single character tokens
char_hashes_bert,char_hashes_stackbert= [],[] # single character tokens preceeded by '##'
for token in bert_tokenizer.vocab.keys():
if len(token) == 1:
char_bert.append(token)
elif len(token) == 3 and token[0:2] == '##':
char_hashes_bert.append(token)
for token in stack_tokenizer.vocab.keys():
if len(token) == 1:
char_stackbert.append(token)
elif len(token) == 3 and token[0:2] == '##':
char_hashes_stackbert.append(token)
print('BERT vocabulary contains,',len(char_bert),'single character tokens','\n')
print('BERTOverflow vocabulary contains,',len(char_stackbert),'single character tokens','\n')
print('BERT vocabulary contains,',len(char_hashes_bert),'single character tokens preceeded by ##','\n')
print('BERTOverflow vocabulary contains,',len(char_hashes_stackbert),'single character tokens preceeded by ##','\n')

Various token lengths in vocabulary
Installing the libraries required
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set(style='darkgrid')
sns.set(font_scale=1.6)
plt.rcParams["figure.figsize"] = (10,5)
token_lengths = [len(token) for token in bert_tokenizer.vocab.keys()]
sns.countplot(token_lengths)
plt.title('BERT Vocab Token Lengths')
plt.xlabel('Token Length')
plt.ylabel('# of Tokens')
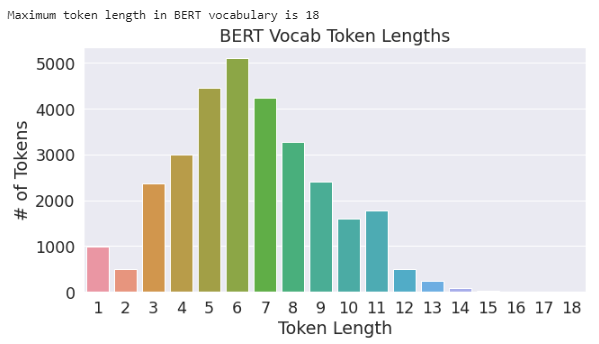
print('Maximum token length in BERT vocabulary is', max(token_lengths))
sns.set(style='darkgrid')
sns.set(font_scale=1.6)
plt.rcParams["figure.figsize"] = (10,5)
token_lengths = [len(token) for token in stack_tokenizer.vocab.keys()]
sns.countplot(token_lengths)
plt.title('OverflowBERT Vocab Token Lengths')
plt.xlabel('Token Length')
plt.ylabel('# of Tokens')
print('Maximum token length in OverflowBERT vocabulary is', max(token_lengths))
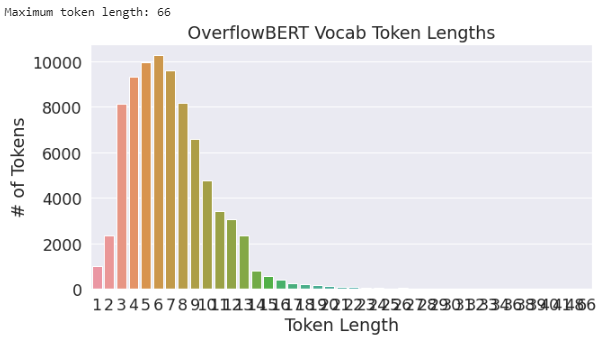
Maximum length token in BERT is ‘Telecommunications’, and surprisingly it’s ‘##0000000000000000000000000000000000000000000000000000000000000000’ in OverflowBERT.
Subwords token lengths in vocabulary
Subwords are tokens preceeded by ‘##’.
bert_subwords = 0
bert_subword_lengths = []
for token in bert_tokenizer.vocab.keys():
if len(token) >= 2 and token[0:2] == '##':
bert_subwords += 1
length = len(token)
bert_subword_lengths.append(length)
vocab_size = len(bert_tokenizer.vocab.keys())
sns.countplot(bert_subword_lengths)
plt.title('Subword Token Lengths')
plt.xlabel('Subword Length')
plt.ylabel('# of Subwords')
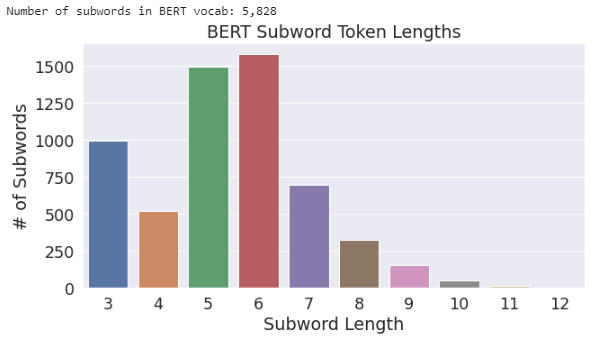
print('Number of subwords in BERT vocab: {:,} '.format(bert_subwords))
stack_subwords = 0
stack_subword_lengths = []
for token in stack_tokenizer.vocab.keys():
if len(token) >= 2 and token[0:2] == '##':
stack_subwords += 1
length = len(token)
stack_subword_lengths.append(length)
vocab_size = len(stack_tokenizer.vocab.keys())
sns.countplot(stack_subword_lengths)
plt.title('Subword Token Lengths')
plt.xlabel('Subword Length')
plt.ylabel('# of Subwords')
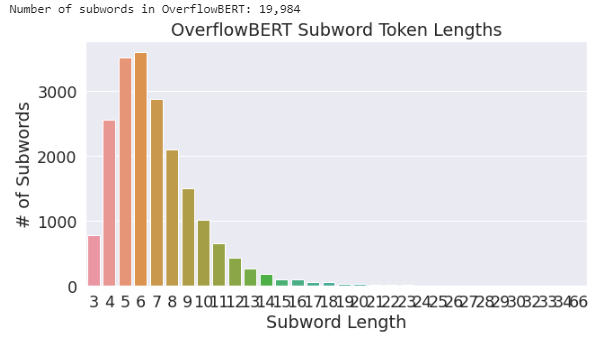
print('Number of subwords in OverflowBERT: {:,}'.format(stack_subwords))
Maximum length subtokens of length 12 in BERT vocabulary are ##orestation, ##ropriation, ##filtration.
As the OverflowBERT was trained on StackOverflow corpus and generic BERT model on WIKIPEDIA corpus, OverflowBERT contains the frequently used terms in StackOverflow questions whereas the BERT model is dividing these terms into subwords.